Ван Син придерживался восходящей к XIV веку военной философии императора Чжу Юаньчжана, лидера армии повстанцев, ставшего первым императором династии Мин: «Строй высокие стены, запасай зерно и жди своего времени, прежде чем претендовать на трон».
Наполеон (Евгений Тарле)
Директория победила, республика была спасена, и победоносный генерал Бонапарт из своего далекого итальянского лагеря горячо поздравляют Директорию (которую он уничтожил спустя два года) со спасением республики (которую он уничтожит спустя семь лет).
«Недалеко уже то время, когда мы почувствуем, что для того, чтобы в самом деле разгромить Англию, нам нужно овладеть Египтом». В течение всей итальянской войны в свободные минуты он, как всегда, много и с жадностью читал, и мы знаем, что он выписал и прочел книгу Вольнэя о Египте и еще несколько работ на ту же тему.
Наполеон очень часто повторял слова, выражавшие крепко сидевшую в нем мысль: «Есть два рычага, которыми можно двигать людей, – страх и личный интерес».
«Попы все-таки лучше, чем шарлатаны вроде Калиостро или Канта или всех этих немецких фантазеров», – говаривал Наполеон, ставя в один ряд авантюриста Калиостро и философа Канта и прибавляя, что раз уж люди так устроены, что хотят верить в разные чудеса, то лучше дать им возможность пользоваться церковью и установленным церковным учением, чем разрешать слишком философствовать.
Самой лучшей армией Наполеон называл ту армию, в которой каждый офицер знает, что делать при данных обстоятельствах.
Что в конечном счете массы решают все, – эту истину Наполеон не переставал повторять. Искусство полководца, во-первых, в том, чтобы уметь добывать, вооружать и быстро обучать большие батальоны, создавать массовые армии; во-вторых, в том, чтобы к моменту нанесения решающего удара они оказались в нужном пункте полностью; в-третьих, в том, чтобы, начиная битву, уметь не щадить эти большие батальоны, если это нужно для выигрыша сражения; в-четвертых, в том, чтобы, собрав эту массу, никогда не избегать и не отсрочивать битву, а искать скорейшей решительной развязки едва только есть шансы победить; в-пятых, и это самое трудное, находить в неприятельском расположении тот пункт, на который нужно направить решающий удар.
Много раз и по разным поводам Наполеон говорил, что все военное искусство заключается в умении сосредоточить в нужный момент и в нужном месте больше сил, чем есть в этот момент в этом месте у противника.
Выигрывает сражение не тот, кто придумал план битвы или нашел нужный выход, а тот, кто взял на себя ответственность за его выполнение.
Не работайте с мудаками (Роберт Саттон)
Эксперименты Коэна, опубликованные в 1996 г. в Journal of Personality and Social Psychology, показывают, что на мужчин — выходцев с Юга Соединенных Штатов культура чести продолжает существенно влиять даже после переезда в северные штаты.
Если вы состоите в группе, взаимодействующей в основном через интернет или по телефону, и если в ней, похоже, окопалась целая стая придурков, то технологии могут скорее разогревать проблему, чем защищать вас от нее. В таких случаях есть смысл потратить время на личные встречи, чтобы понять, с каким прессингом сталкиваются люди, и укрепить доверие.
Милый друг (Ги де Мопассан) – описание пригородов Парижа
На необъятной равнине, расстилавшейся прямо против них, кое-где виднелись деревни. Среди чахлой зелени маленькой рощи резкими светлыми пятнами выделялись пруды Везине. Налево, где-то совсем далеко, тянулась к небу остроконечная колокольня Сартрувиля.
— Нигде в мире нет такой панорамы, — заметил Вальтер. — Даже в Швейцарии не встретишь ничего подобного.
Карета отвезет нас в Севр, и там мы переночуем. А завтра поедем в Ларош-Гийон. Это красивая деревня на берегу Сены, между Мантом и Боньером.
The Kubernetes Book (Poulton, Nigel)
Like many of the modern cloud-native projects, it’s written in Go (Golang), it lives on Github at kubernetes/kubernetes, it’s actively discussed on the IRC channels, you can follow it on Twitter (@kubernetesio), and slack.k8s.io is a pretty good slack channel.
As well as reading this book, I suggest you follow @kubernetesio on Twitter
If you do not have a cluster but would like to follow along, go to http://play-with-k8s.com and build a quick cluster. It’s free and easy.
kubectl get command offers a couple of really simple flags that give you more information: The -o wide flag gives a couple more columns but is still a single line of output. The -o yaml flag takes things to the next level. It returns a full copy of the Pod manifest from the cluster store. The output is broadly divided into two parts: desired state (.spec) current observed state (.status)
You can see a full list of API resources, and their shortnames, using the kubectl api-resources command. The output of the command shows; the API group that each resource belongs to (an empty string indicates the core API group), if the resource is namespaced, and what its equivalent kind is when writing YAML files.
Брама Європи. Історія України від скіфських воєн до незалежності (Сергій Плохій)
За шість років, у період між 1991 і 1997 роками, українське промислове виробництво скоротилося на 48 %, у той час як валовий внутрішній продукт (ВВП) втратив приголомшливі 60 %. Найбільша втрата (23 % від ВВП попереднього року) сталася 1994 року, в рік президентських виборів та підписання першої угоди про співпрацю з ЄС. Якщо порівнювати ці цифри, то вони значно більші, ніж економічні втрати США під час Великої депресії, коли промислове виробництво скоротилося на 45 %, а ВВП на 30 %.
У період з 1989 до 2006 року більш ніж 1,5 мільйона радянських євреїв покинули свої країни проживання, в тому числі чимало євреїв України. Якщо українське населення в цілому за період з 1989 до 2001 року зменшилося приблизно на 5 %, то частка євреїв упала на 78 %, скоротившись з 487 300 до 105 500 осіб. Серед тих, хто виїхав, були сім’ї співзасновників «Paypal» (Макс Левчин) та «WhatsApp» (Ян Кум).
Не менш важливим є питання про природу національного будівництва України, в тому числі про роль історії, етнічного походження, мови та культури в творенні української політичної нації. Чи може держава, громадяни якої представлені різними етнічними групами, говорять різними (більш ніж однією) мовами, належать до різних церков і населяють різні історичні області, протистояти не лише натиску потужної у військовому відношенні сусідньої держави, а й претензіям цієї держави на вірність усіх, хто говорить російською чи відвідує православну церкву? Російська агресія була спрямована на поділ України за мовною, етнічною та релігійною ознаками. Незважаючи на те що ця тактика в деяких місцях спрацювала, більшість українців об’єдналися навколо ідеї багатомовної та мультикультурної нації, об’єднаної політичними та адміністративними зв’язками. Ця ідея, народжена уроками, які Україна винесла зі своєї важкої і часто трагічної історії внутрішніх поділів, спирається на традиції співіснування різних мов, культур і релігій упродовж століть. Українське суспільство здивувало й себе, і світ, прочитавши свою історію в спосіб, який забезпечив подальше майбутнє своєї країни.
Sapiens. Краткая история человечества (Юваль Ной Харари)
Все перечисленные разделения – на свободных и рабов, белых и черных, богатых и бедных – коренятся в человеческом воображении. (О разделении на мужчин и женщин поговорим позже.) Однако в истории действует железное правило: любая воображаемая иерархия отрицает свою вымышленность и провозглашает себя естественной и необходимой.
Уже в 48 году н. э. император Клавдий принял в сенат нескольких галльских аристократов, заявив при этом, что они «обычаями, культурой и узами брака соединены с нами». Снобы-сенаторы возмутились: как это, недавних врагов впустить в самое сердце римской политической системы?! И тогда Клавдий напомнил им о том, о чем они предпочли забыть: сенаторские семьи по большей части происходили от италийских племен, которые во время оно сражались против Рима, а потом получили римское гражданство. И даже сам Клавдий, владыка Рима, свой род возводил к сабинянам. Во II веке н. э. Римом правила династия императоров из Иберии, вероятно, с примесью иберийской крови. Именно эта эпоха – Траяна, Адриана, Антонина Пия и Марка Аврелия – считается золотым веком империи. Рухнули все внутренние этнические барьеры. Император Септимий Север (193–211) был отпрыском поселившегося в Ливии карфагенского рода. Гелиогабал (218–222) был сирийцем. Императора Филиппа I (244–249) прозвали Арабом. Новые граждане с таким энтузиазмом перенимали культуру императорского Рима, что спустя многие столетия после распада империи они все еще говорили на ее языке, сохраняли христианскую религию, пришедшую из левантийской провинции, и следовали законам империи.
23 августа 1572 года французские католики, так ценившие добрые дела, напали на французских протестантов, которые большее значение придавали Божьей любви к людям. За сутки в этой резне, запомнившейся под именем Варфоломеевской ночи, погибло от пяти до десяти тысяч протестантов. Услышав эту новость, папа римский возликовал, назначил праздничный молебен и заказал Джорджо Вазари фреску, которая должна была увековечить сцены убийств (теперь это помещение Ватикана закрыто для посетителей). За 24 часа от рук христиан погибло больше христиан – пусть и иной конфессии, – чем за всю историю гонений в Римской империи.
На пике (Брэд Сталберг, Стив Магнесс)
Исследование показывает, что когда мы видим, как кто-то другой выражает чувства счастья или грусти (то есть улыбается или хмурится), в нашем мозге активируется связанная с этими эмоциями нейронная сеть. То же касается боли. Один вид страдающего человека активирует наш собственный нейронный отклик на боль. Это объясняет, почему мы плачем во время печальных фильмов, чувствуем подъем среди счастливых друзей и кривимся, когда видим, что кому-то больно. По словам психолога Стэнфордского университета профессора Эммы Сеппала, «мы запрограммированы на эмпатию».
«Культура ест стратегию на завтрак».
Помните, что, когда вы демонстрируете мотивацию и положительный настрой, вы помогаете не только себе, но и всем, кто вас окружает. К сожалению, негативное отношение и пессимизм также заразны. Не смиряйтесь с ними. Цепь сильна лишь настолько, насколько сильно ее самое слабое звено.
По возможности связывайте свою деятельность с какой-либо великой целью. И тогда, если вы столкнетесь с серьезными затруднениями и ваш разум посоветует вам все бросить, вы сможете спросить себя, зачем вы это делаете. Если ответом будет: «Я делаю это для кого-то или чего-то, что превыше меня», то вы, скорее всего, сможете пробиться.
Меньше думать о себе — это лучший способ развить себя.
The DevOps Handbook (Gene Kim)
“In any value stream, there is always a direction of flow, and there is always one and only constraint; any improvement not made at that constraint is an illusion.”
“five focusing steps”: Identify the system’s constraint. Decide how to exploit the system’s constraint. Subordinate everything else to the above decisions. Elevate the system’s constraint. If in the previous steps a constraint has been broken, go back to step one, but do not allow inertia to cause a system constraint.
The effectiveness of approval processes decreases as we push decision-making further away from where the work is performed. Doing so not only lowers the quality of decisions but also increases our cycle time, thus decreasing the strength of the feedback between cause and effect, and reducing our ability to learn from successes and failures.
we enable the product teams to get what they need, when they need it, as well as reduce the need for communications and coordination. As Damon Edwards observed, “Without these self-service Operations platforms, the cloud is just Expensive Hosting 2.0.”
Note that canary releases require having multiple versions of our software running in production simultaneously. However, because each additional version we have in production creates additional complexity to manage, we should keep the number of versions to a minimum. This may require the use of the expand/contract database pattern described earlier.
One sophisticated example of such a service is Facebook’s Gatekeeper, an internally developed service that dynamically selects which features are visible to specific users based on demographic information such as location, browser type, and user profile data (age, gender, etc.). For instance, a particular feature could be configured so that it is only accessible by internal employees, 10% of their user base, or only users between the ages of twenty-five and thirty-five. Other examples include the Etsy Feature API and the Netflix Archaius library.
In The Art of Monitoring, James Turnbull describes a modern monitoring architecture, which has been developed and used by Operations engineers at web-scale companies (e.g., Google, Amazon, Facebook).
Business level: Examples include the number of sales transactions, revenue of sales transactions, user signups, churn rate, A/B testing results, etc. Application level: Examples include transaction times, user response times, application faults, etc. Infrastructure level (e.g., database, operating system, networking, storage): Examples include web server traffic, CPU load, disk usage, etc. Client software level (e.g., JavaScript on the client browser, mobile application): Examples include application errors and crashes, user measured transaction times, etc. Deployment pipeline level: Examples include build pipeline status (e.g., red or green for our various automated test suites), change deployment lead times, deployment frequencies, test environment promotions, and environment status.
Etsy open-sourced their experimentation framework Feature API (formerly known as the Etsy A/B API), which not only supports A/B testing but also online ramp-ups, enabling throttling exposure to experiments. Other A/B testing products include Optimizely, Google Analytics, etc.
Ronny Kohavi, Distinguished Engineer and General Manager of the Analysis and Experimentation group at Microsoft, observed that after “evaluating well-designed and executed experiments that were designed to improve a key metric, only about one-third were successful at improving the key metric!” In other words, two-thirds of features either have a negligible impact or actually make things worse.
One of the core beliefs in the Toyota Production System is that “people closest to a problem typically know the most about it.”
when asked to describe a great pull request that indicates an effective review process, Tomayko quickly listed off the essential elements: there must be sufficient detail on why the change is being made, how the change
Ian Malpass, an engineer at Etsy observes, “In that moment when we do something that causes the entire site to go down, we get this ‘ice water down the spine’ feeling, and likely the first thought through our head is, ‘I suck and I have no idea what I’m doing.’ We need to stop ourselves from doing that, as it is route to madness, despair, and feelings of being an imposter, which is something that we can’t let happen to good engineers. The better question to focus on is, ‘Why did it make sense to me when I took that action?’”
Distributed systems for fun and profit (Mikito Takada)
Every concept originates through our equating what is unequal. No leaf ever wholly equals another, and the concept “leaf” is formed through an arbitrary abstraction from these individual differences, through forgetting the distinctions; and now it gives rise to the idea that in nature there might be something besides the leaves which would be “leaf” – some kind of original form after which all leaves have been woven, marked, copied, colored, curled, and painted, but by unskilled hands, so that no copy turned out to be a correct, reliable, and faithful image of the original form.
Byzantine fault tolerance. Byzantine faults are rarely handled in real world commercial systems, because algorithms resilient to arbitrary faults are more expensive to run and more complex to implement.
Several computers (or nodes) achieve consensus if they all agree on some value. More formally: Agreement: Every correct process must agree on the same value. Integrity: Every correct process decides at most one value, and if it decides some value, then it must have been proposed by some process. Termination: All processes eventually reach a decision. Validity: If all correct processes propose the same value V, then all correct processes decide V.
CA (consistency + availability). Examples include full strict quorum protocols, such as two-phase commit. CP (consistency + partition tolerance). Examples include majority quorum protocols in which minority partitions are unavailable such as Paxos. AP (availability + partition tolerance). Examples include protocols using conflict resolution, such as Dynamo.
ACID consistency != CAP consistency != Oatmeal consistency
Consistency model a contract between programmer and system, wherein the system guarantees that if the programmer follows some specific rules, the results of operations on the data store will be predictable The “C” in CAP is “strong consistency”, but “consistency” is not a synonym for “strong consistency”.
Ореховый Будда (Борис Акунин)
Не старайся всё сразу усвоить и понять. Знания – как зерна. Одни засохнут, другие прорастут.
– Умному и хитрому человеку в России жить выгодно, – говорил Ян, ведя постояльцев по мосту обратно в город. – Нужно только знать правила. Здесь кажется, что всё нельзя, а на самом деле почти всё можно. Симпэй кивал, думая: вот обычный урок, который извлекает слепец, бредя жизненной дорогой, но не видя Пути. На самом деле всё наоборот. Кажется, что тебе всё можно, но хорошему путнику почти всё нельзя. Только идти вперед.
Не старайся всё сразу усвоить и понять. Знания – как зерна. Одни засохнут, другие прорастут.
Стресс как внутренняя игра (Тимоти Голви, Эдд Ханзелик, Джон Хортон)
Один чрезвычайно занятый корпоративный юрист, посещавший наш семинар, однажды упомянул, что ему было так трудно выделить время для физических упражнений, что он купил оборудование для домашнего тренажерного зала и нанял личного тренера, который приходил к нему на дом. И вот как-то раз утром, занимаясь на тренажере под руководством тренера, он выглянул на улицу. День стоял прекрасный, садовник копался в саду. И тут юриста осенило. «Я понял, что плачу тренеру за занятия, плачу за тренажерное оборудование и плачу садовнику. И подумал, что, возможно, если бы я сам занялся садом, то достиг бы сразу трех целей: не платил бы за тренера и оборудование, наслаждался бы физическим трудом на свежем воздухе и при этом еще и улучшал бы свой сад».
A complex system that works is invariably found to have evolved from a simple system that worked. A complex system designed from scratch never works and cannot be patched up to make it work. You have to start over with a working simple system. – John Gall (1975, p.71)
Преодолевая препятствия одно за другим, ты будешь действовать в соответствии с пословицей: “Чем больше воды, тем выше корабль”
Designing Autonomous Teams and Services (Nick Tune and Scott Millett)
Lack of ownership leads to blame culture
Alistair Hann of SkyScanner Engineering claims, “We may get to 10,000 releases per day at the end of next year [2017].”
Puppet 2017 State of DevOps Report: Loosely coupled architectures and teams are the strongest predictor of continuous delivery. If you want to achieve higher IT performance, start shifting to loosely coupled services—services that can be developed and released independently of each other—and loosely coupled teams, which are empowered to make changes.
…teams will be primed for innovation, with few dependencies to get in their way.
bit.ly/alignment-experiment
Explore, Exploit, Sustain, Retire framework
See “How Google Sets Goals: OKRs” for more information.
See “Alignment at Scale—Or How to Not Get Totally Unagile with Lots of Teams” for more information.
Aligning teams and software systems with domain cohesion minimizes organizational and technical dependencies—the holy grail of autonomy.
Конструкции, или почему не ломаются вещи
В самом деле, играя в теннис или спускаясь по лестнице, мы с помощью аналогового компьютера нашего мозга быстро, легко, не задумываясь, решаем дифференциальные уравнения, которые могли бы занять многие страницы. Что мы действительно находим трудным, так это формальное преподавание математики с пристрастием к символам и догме, доходящим до садизма.
A Mind For Numbers: How to Excel at Math and Science (Even If You Flunked Algebra) (Oakley, Barbara)
“What would you do if you weren’t afraid?”
Be willing to be disagreeable. There is a negative correlation between the level of creativity and “agreeableness,” so those who are the most disagreeable tend to be most creative.
See Joshua Foer’s masterful TED talk for a demonstration of the memory palace technique for remembering speeches.
(Great flash card systems like Anki have built in algorithms that repeat on a scale ranging from days to months.)
Chess masters, emergency room physicians, fighter pilots, and many other experts often have to make complex decisions rapidly. They shut down their conscious system and instead rely on their well-trained intuition, drawing on their deeply ingrained repertoire of chunks.2 At some point, self-consciously “understanding” why you do what you do just slows you down and interrupts flow, resulting in worse decisions.
Джедайские техники (Максим Дорофеев)
В любой непонятной ситуации — думай.
Даниэль Канеман, «ничто в жизни не важно настолько, насколько вам кажется, когда вы об этом думаете».
Фактически это означает, что дело, которое в данный момент находится в вашей рабочей памяти (то, о котором вы думаете), автоматически получает дополнительный (часто очень значительный) бонус к воспринимаемой важности.
Бонус к ощущению воспринимаемой важности прямо пропорционален степени вашей внутренней тревоги: чем больше вы встревожены, тем более важной и значительной начинает казаться любая мелочь, засевшая в вашей голове. Чтобы оценить, насколько адекватно вы оцениваете важность и срочность текущей ситуации, можно использовать очень простой тест «Субъективная минута»
Попытки сделать всю работу перед тем, как заняться собой (нарушение принципа кислородной маски)
Нельзя: Складывать задачи на сегодня, опираясь на соображения «надо то и это, и вот это тоже», без проверки на впихиваемость, и пытаться любой ценой выполнить их именно сегодня (то есть впихивать заведомо невпихиваемое и корить себя за то, что оно не впихнулось) Да, даже в случае форс-мажоров. Более того, форс-мажор — сам по себе причина посмотреть еще раз, что из списка можно сегодня не делать.
Можно: Нагребать на день меньше задач, чем можно сделать, — и потом либо отдыхать, либо набрать еще из недельных. Нагребать на день больше задач, чем можно сделать, — при условии, что: есть внятный алгоритм, как понять, какую задачу делать следующей; этот алгоритм не жрет мыслетопливо; ситуация, когда сделаны не все задачи, не считается преступлением. (Несделанные можно либо вернуть в неделю, либо вычистить из списка (и не сделаю, и ну их!)).
Architecting for the AWS Cloud: Best Practices (AWS Whitepaper) (Amazon Web Services;AWS Whitepapers)
If the client can try every endpoint in a set of sharded resources, until one succeeds, you get a dramatic improvement. This technique is called shuffle sharding and is described in more detail in the relevant blog post – Shuffle Sharding: Massive and Magical Fault Isolation
Strong Consistency – Reads see all previous writes.
Eventual Consistency – Reads see subset of previous writes.
Consistent Prefix – Reads see an initial sequence of writes.
Bounded Staleness – Reads see all “old” writes.
Monotonic Reads – Reads see an increasing subset of writes.
Read My Writes – Reads see all writes performed by the reader.
Chapter from “Designing Data-Intensive applications” book:
Reading Your Own Writes
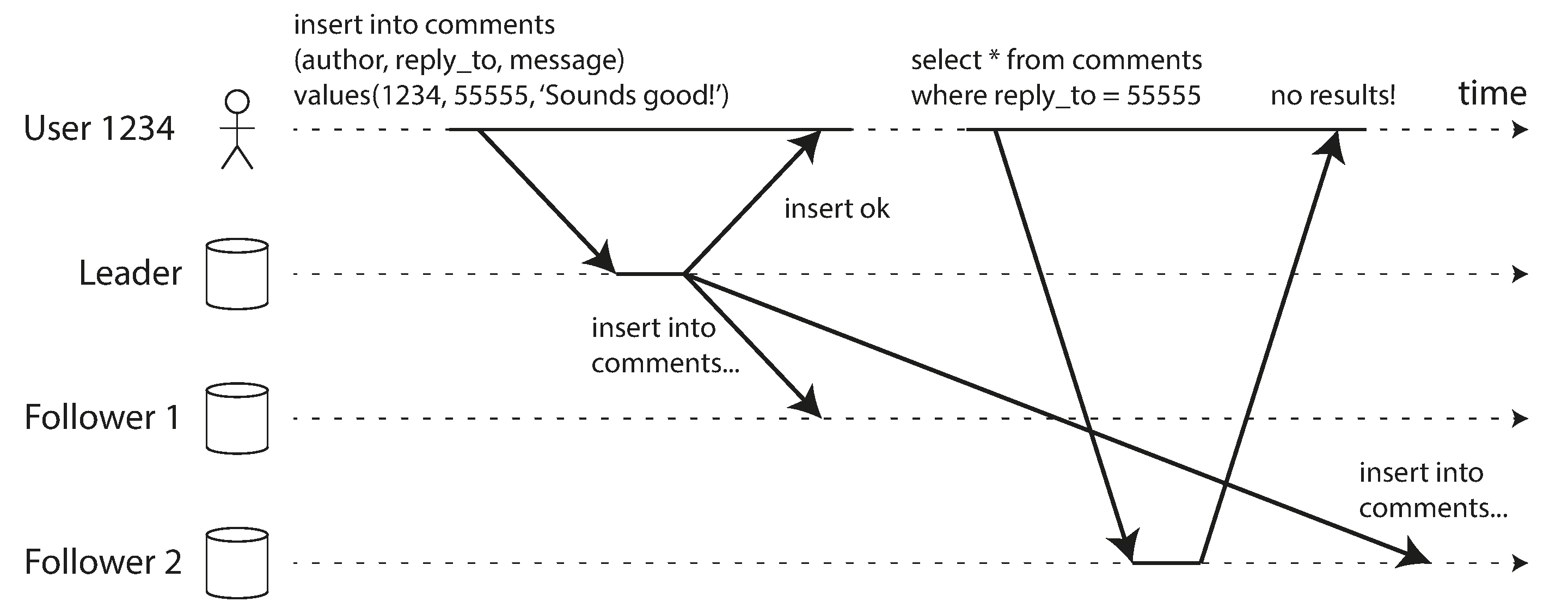
Many applications let the user submit some data and then view what they have submitted. This might be a record in a customer database, or a comment on a discussion thread, or something else of that sort. When new data is submitted, it must be sent to the leader, but when the user views the data, it can be read from a follower. This is especially appropriate if data is frequently viewed but only occasionally written.
With asynchronous replication, there is a problem: if the user views the data shortly after making a write, the new data may not yet have reached the replica. To the user, it looks as though the data they submitted was lost, so they will be understandably unhappy.
A user makes a write, followed by a read from a stale replica. To prevent this anomaly, we need read-after-write consistency.
In this situation, we need read-after-write consistency, also known as read-your-writes consistency [24]. This is a guarantee that if the user reloads the page, they will always see any updates they submitted themselves. It makes no promises about other users: other users’ updates may not be visible until some later time. However, it reassures the user that their own input has been saved correctly.
How can we implement read-after-write consistency in a system with leader-based replication? There are various possible techniques. To mention a few:
When reading something that the user may have modified, read it from the leader; otherwise, read it from a follower. This requires that you have some way of knowing whether something might have been modified, without actually querying it. For example, user profile information on a social network is normally only editable by the owner of the profile, not by anybody else. Thus, a simple rule is: always read the user’s own profile from the leader, and any other users’ profiles from a follower.
If most things in the application are potentially editable by the user, that approach won’t be effective, as most things would have to be read from the leader (negating the benefit of read scaling). In that case, other criteria may be used to decide whether to read from the leader. For example, you could track the time of the last update and, for one minute after the last update, make all reads from the leader. You could also monitor the replication lag on followers and prevent queries on any follower that is more than one minute behind the leader.
The client can remember the timestamp of its most recent write—then the system can ensure that the replica serving any reads for that user reflects updates at least until that timestamp. If a replica is not sufficiently up to date, either the read can be handled by another replica or the query can wait until the replica has caught up. The timestamp could be a logical timestamp (something that indicates ordering of writes, such as the log sequence number) or the actual system clock (in which case clock synchronization becomes critical; see “Unreliable Clocks”).
If your replicas are distributed across multiple datacenters (for geographical proximity to users or for availability), there is additional complexity. Any request that needs to be served by the leader must be routed to the datacenter that contains the leader.
Another complication arises when the same user is accessing your service from multiple devices, for example a desktop web browser and a mobile app. In this case you may want to provide cross-device read-after-write consistency: if the user enters some information on one device and then views it on another device, they should see the information they just entered.
In this case, there are some additional issues to consider:
Approaches that require remembering the timestamp of the user’s last update become more difficult, because the code running on one device doesn’t know what updates have happened on the other device. This metadata will need to be centralized.
If your replicas are distributed across different datacenters, there is no guarantee that connections from different devices will be routed to the same datacenter. (For example, if the user’s desktop computer uses the home broadband connection and their mobile device uses the cellular data network, the devices’ network routes may be completely different.) If your approach requires reading from the leader, you may first need to route requests from all of a user’s devices to the same datacenter.
Monotonic Reads
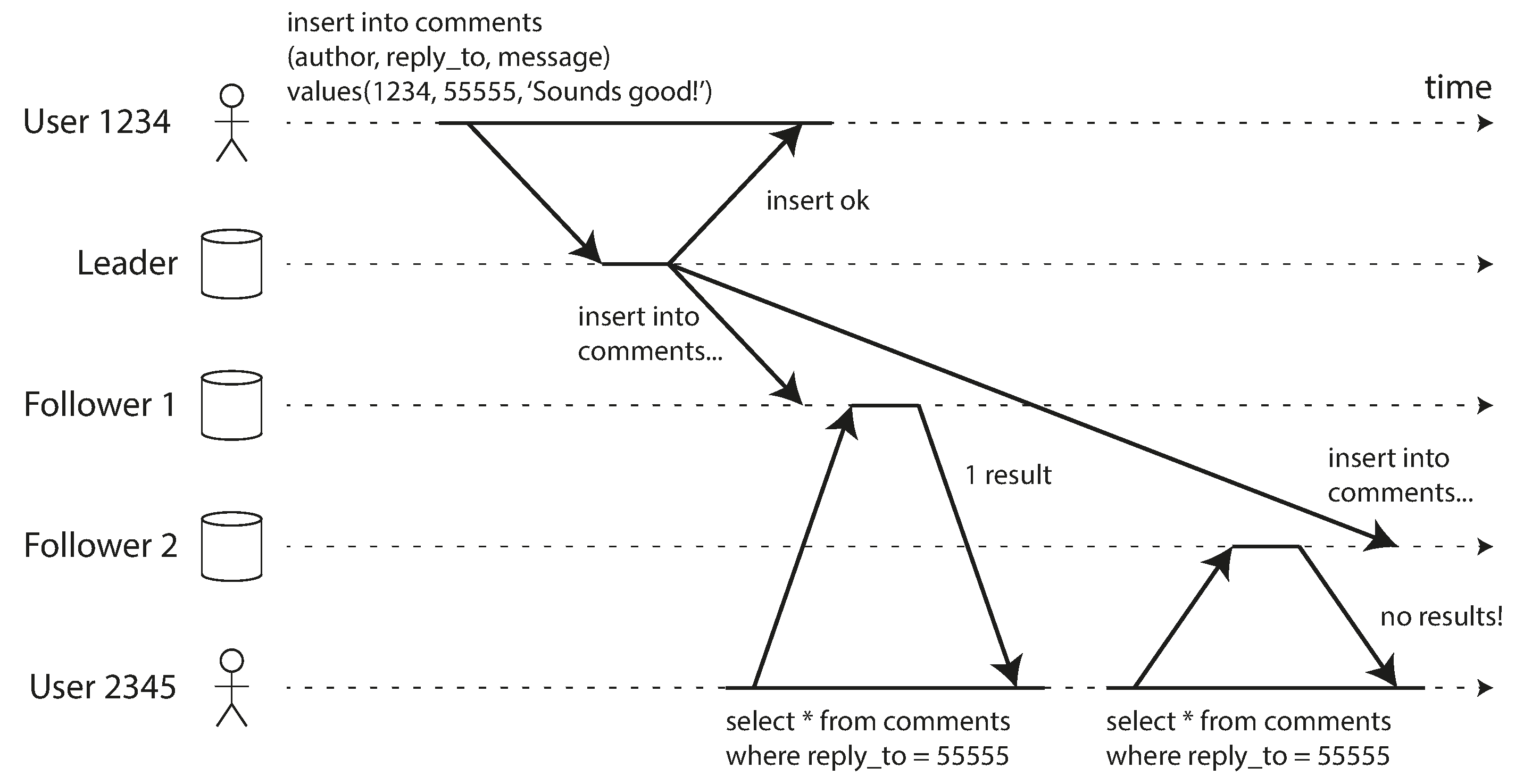
Our second example of an anomaly that can occur when reading from asynchronous followers is that it’s possible for a user to see things moving backward in time.
This can happen if a user makes several reads from different replicas. For example, image shows user 2345 making the same query twice, first to a follower with little lag, then to a follower with greater lag. (This scenario is quite likely if the user refreshes a web page, and each request is routed to a random server.) The first query returns a comment that was recently added by user 1234, but the second query doesn’t return anything because the lagging follower has not yet picked up that write. In effect, the second query is observing the system at an earlier point in time than the first query. This wouldn’t be so bad if the first query hadn’t returned anything, because user 2345 probably wouldn’t know that user 1234 had recently added a comment. However, it’s very confusing for user 2345 if they first see user 1234’s comment appear, and then see it disappear again.
A user first reads from a fresh replica, then from a stale replica. Time appears to go backward. To prevent this anomaly, we need monotonic reads.
Monotonic reads is a guarantee that this kind of anomaly does not happen. It’s a lesser guarantee than strong consistency, but a stronger guarantee than eventual consistency. When you read data, you may see an old value; monotonic reads only means that if one user makes several reads in sequence, they will not see time go backward—i.e., they will not read older data after having previously read newer data.
One way of achieving monotonic reads is to make sure that each user always makes their reads from the same replica (different users can read from different replicas). For example, the replica can be chosen based on a hash of the user ID, rather than randomly. However, if that replica fails, the user’s queries will need to be rerouted to another replica.
Consistent Prefix Reads
Our third example of replication lag anomalies concerns violation of causality. Imagine the following short dialog between Mr. Poons and Mrs. Cake:
Mr. Poons
How far into the future can you see, Mrs. Cake?
Mrs. Cake
About ten seconds usually, Mr. Poons.
There is a causal dependency between those two sentences: Mrs. Cake heard Mr. Poons’s question and answered it.
Now, imagine a third person is listening to this conversation through followers. The things said by Mrs. Cake go through a follower with little lag, but the things said by Mr. Poons have a longer replication lag. This observer would hear the following:
Mrs. Cake
About ten seconds usually, Mr. Poons.
Mr. Poons
How far into the future can you see, Mrs. Cake?
To the observer it looks as though Mrs. Cake is answering the question before Mr. Poons has even asked it. Such psychic powers are impressive, but very confusing.
If some partitions are replicated slower than others, an observer may see the answer before they see the question.
Preventing this kind of anomaly requires another type of guarantee: consistent prefix reads. This guarantee says that if a sequence of writes happens in a certain order, then anyone reading those writes will see them appear in the same order.
This is a particular problem in partitioned (sharded) databases, which we will discuss in Chapter 6. If the database always applies writes in the same order, reads always see a consistent prefix, so this anomaly cannot happen. However, in many distributed databases, different partitions operate independently, so there is no global ordering of writes: when a user reads from the database, they may see some parts of the database in an older state and some in a newer state.
One solution is to make sure that any writes that are causally related to each other are written to the same partition—but in some applications that cannot be done efficiently. There are also algorithms that explicitly keep track of causal dependencies, a topic that we will return to in “The “happens-before” relationship and concurrency”.
Solutions for Replication Lag
When working with an eventually consistent system, it is worth thinking about how the application behaves if the replication lag increases to several minutes or even hours. If the answer is “no problem,” that’s great. However, if the result is a bad experience for users, it’s important to design the system to provide a stronger guarantee, such as read-after-write. Pretending that replication is synchronous when in fact it is asynchronous is a recipe for problems down the line.
As discussed earlier, there are ways in which an application can provide a stronger guarantee than the underlying database—for example, by performing certain kinds of reads on the leader. However, dealing with these issues in application code is complex and easy to get wrong.
It would be better if application developers didn’t have to worry about subtle replication issues and could just trust their databases to “do the right thing.” This is why transactions exist: they are a way for a database to provide stronger guarantees so that the application can be simpler.
Single-node transactions have existed for a long time. However, in the move to distributed (replicated and partitioned) databases, many systems have abandoned them, claiming that transactions are too expensive in terms of performance and availability, and asserting that eventual consistency is inevitable in a scalable system. There is some truth in that statement, but it is overly simplistic, and we will develop a more nuanced view over the course of the rest of this book.
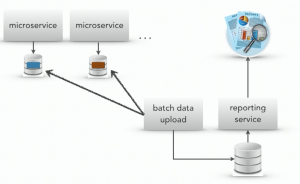
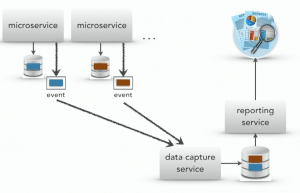
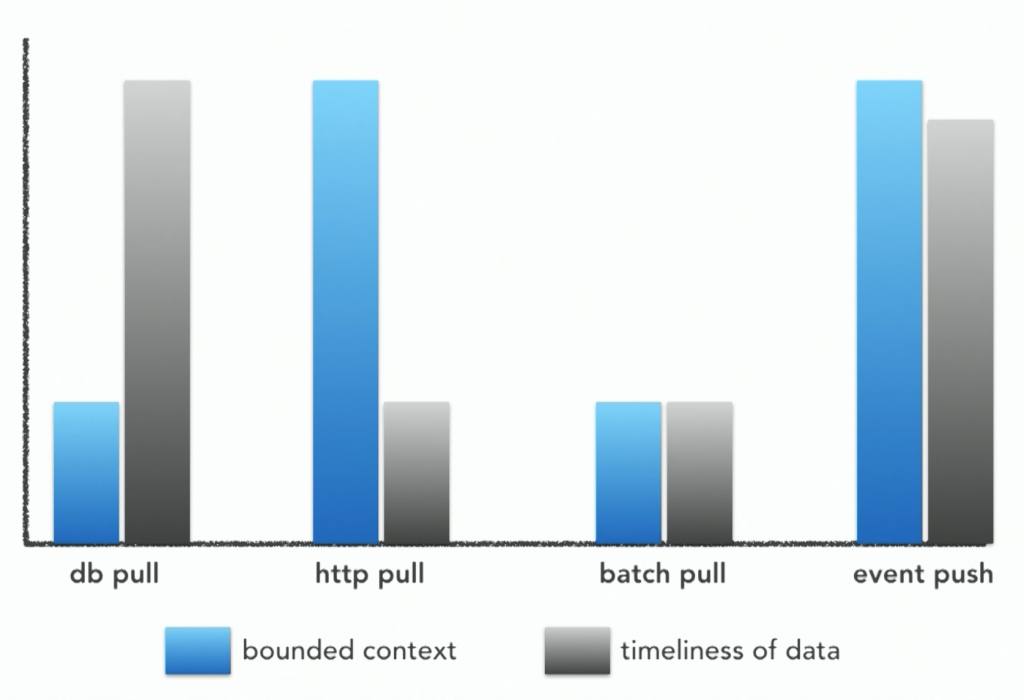
Comparison of different approaches on how to build reporting service over distributed system.
Database pull model: reporting system has direct access to service database. Data context is not bounded to specific service.
HTTP pull model: reporting system has access only to API of the service. Data context is encapsulated, but speed of report generation is degrading quickly with growth of services amount.
Batch pull model: data context is not bounded, reports are generated over long period of times.
Event-based push model: solves bounded context problem and performance issues, although adds complexity to services – each of them has to know how and which data to push